SQL基础
实际上数据库范式不止3种,但大家熟知的就三种。
第一范式
所有列应该不可再分
比如,往contact列存储”18257500000,杭州,523839000@qq.com“是比较糟糕的做法,因为此时该列包含了phone、address、email三个维度的数据,应该拆成phone、address、email三个字段分别存储,这样对更新和查询都有好处。
第二范式
必须存在业务主键,且非主键字段应该依赖于全部业务主键(之所以写“全部”,因为可能存在复合主键)
说人话就是:每张表最好都设定主键。虽然某些列可能具备主键的特质(比如user表的id_card),但个人认为主键最好与业务无关,比如自增id。
| id | xxx | yyy | zzz | … |
|---|---|---|---|---|
| 1 | … | … | … | … |
第三范式:
非主键列不能依赖除主键列以外的其他列
听起来很抽象,举个例子就明白了:
| t_student | ||||
|---|---|---|---|---|
| id | stu_name | stu_age | teacher_name | teacher_age |
| 1 | 张三 | 18 | 李四 | 40 |
上面这张t_student表就违反了第三范式:非主键列teacher_name、teacher_age并不依赖id(学生的)。这种做法被称为“冗余”,它的弊端是有可能导致数据不一致。比如t_teacher表数据更新了,李四的age变成41,而代码里却没有及时维护t_student表的数据,就会导致从t_student表查出来的数据中,李四还是40岁。
改写成符合第三范式的设计:
| t_student | |||
|---|---|---|---|
| id | stu_name | stu_age | teacher_id |
| 1 | 张三 | 18 | 10086 |
| t_teacher | |||
|---|---|---|---|
| id | teacher_name | teacher_age | address |
| 10086 | 李四 | 40 | hangzhou |
总结一下三范式:
每一列字段应该不可再分,职责单一
要有主键,最好是与业务无关的自增id
不要有冗余字段,为了避免数据更新不一致,应该拆成两张表,用(逻辑)外键关联
一般来说,前两个范式大家都会遵守,但第三范式有时会被打破(就像上面的t_student一样)。因为实际工作中,越遵从范式化设计,表的拆分越细致,查询时需要关联的表就越多。
比如:
1 | SELECT t1.aaa, t2.bbb, t3.ccc |
此时我们可以适当反范式化设计(反第三范式),目的是减少查询时需要关联的表的数量从而提升查询性能:
1 | SELECT t1.aaa, t1.bbb, t1.ccc |
所以才会出现上面t_student表里冗余teacher_name和teacher_age的设计。
但不论范式化设计还是反范式化设计,都不能过度:
- 遵守第三范式,有时会让查询变得非常麻烦,要么JOIN关联,要么内存中匹配,甚至干脆无法满足需求
- 不遵守第三范式,则需要主动维护冗余数据,避免造成数据更新不一致
但有些场景下,冗余数据百利而无一害。举个例子,比如订单表中的商品价格。商品价格会随着时间发生改变(促销等),而订单表只需记录当前下单的价格即可,不需要更新,否则你双11花了2999买的手机,过几天查询订单发现价格变成了3200,会怀疑自己是不是多付了。
数据类型选择
分类的方法很多,但这里只按自己的理解及使用频率分为4大类:
整数类型
字符类型
小数类型
时间类型
整数类型
数值类型唯一需要注意的3点:
如果业务允许,尽量设置unsigned
int(11)里的11和占用字节大小无关
注意各个类型的选取标准
所谓unsigned,即无符号。比如tinyint,正常取值范围是-128127。但实际业务中很少需要用到负数,比如年龄、身高等都是整数,最小为0。此时使用unsigned可以让正向范围翻倍:0255。
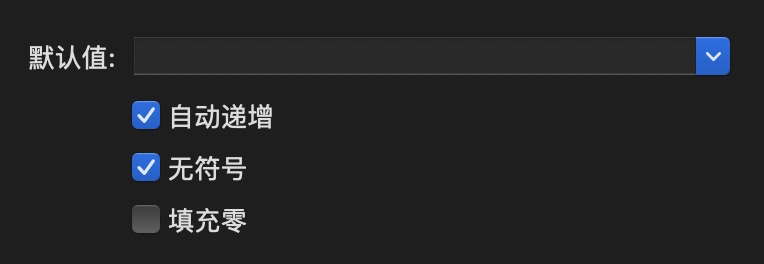

如果业务需要,可以为当前字段设置默认值,比如文章状态status默认0,表示“待审核”。
另外,关于int(11)里的11,很多人都不是很清楚。其实括号里的数字和占用字节大小无关,哪怕你写成int(1)也不代表它比int(11)省空间,这只是列宽表示,比如位数不够就前面补零啥的,但对实际数值大小没有影响。总之,对于数值类型来说,每种类型占用空间大小是固定的。
来看一下各种数值类型的占用空间:
| 数据类型 | 占据空间 | 范围(有符号) | 范围(无符号) | 描述 |
|---|---|---|---|---|
| tinyint | 1 个字节 | -2^7 ~ 2^7-1 | 0 - 255 | 小整数值 |
| smallint | 2 个字节 | -2^15 ~ 2^15-1 | 0 - 65535 | 大整数值 |
| mediumint | 3 个字节 | -2^23 ~ 2^23-1 | 0 - 16777215 | 大整数值 |
| int | 4 个字节 | -2^31 ~ 2^31-1 | 0 - 4294967295 | 大整数值 |
| bigint | 8 个字节 | -2^63 ~ 2^63-1 | 0 - 18446744073709551615 | 极大整数值 |
选择数值类型时,最重要的规则是“够用就好”。比如对于“性别”或“年龄”,用tinyint足够了,毕竟还没听过有人活过250岁的。这里并不是为了省磁盘空间而去扣这些细节,毕竟磁盘是最不值钱的,主要关系到索引。后面会解释,总之记住“够用就好”。
通常来说:
主键id用bigint
age、height等普通数据用int
deleted、status、type用tinyint
之前听说有些公司对于只有0、1两种状态的字段使用bit,也…行吧,按公司的约定来吧。隐约听过有坑,但我自己试了下没发现。大家没啥事可以自己去试试各种类型,做做实验:
此处为语雀视频卡片,点击链接查看:Kapture 2020-12-29 at 23.26.36.mp4
字符类型
平时大家会经常看到char(8)或者varchar(255)这样的形式对吧?经过上面的学习,你可能会觉得:哦,这也是显示作用,和实际大小无关。
那你就错了。
字符类型的数字和实际大小有关,准确地说这里的数值和实际存储大小的上限有关。比如char(3),表示会固定占用3个字符空间,即使存储的值不够3个字符,照样会占着那块空间,但不能超过3个字符:

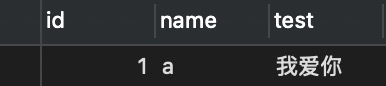
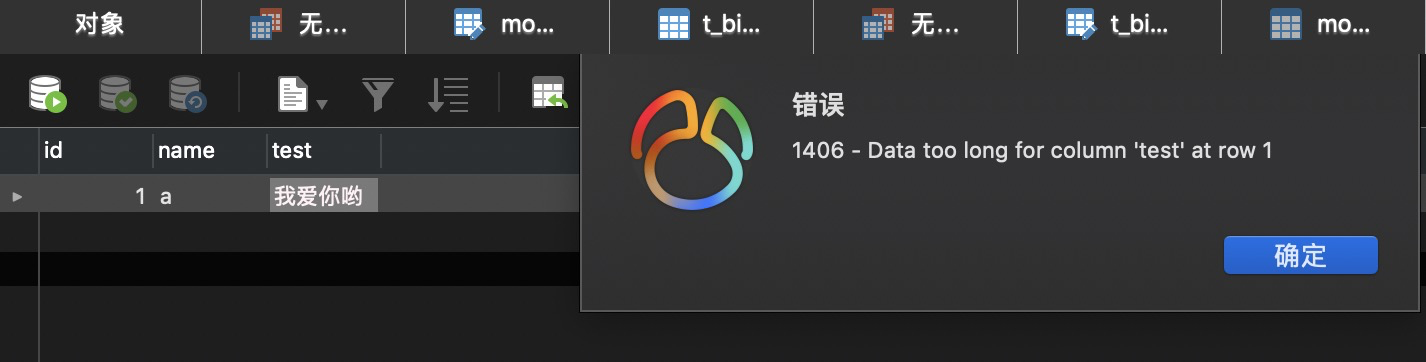
实际开发中,一不小心就会出现上面的报错信息,此时你应该要意识到这是字符超过规定长度了。
至于varchar(255),表示最多存储255个字符。看起来好像和char(255)没区别?实际上,char和varchar分别代表着两种类型:定长与变长。
比如int、bigint这些都是定长,而varchar是变长。
varchar作为“变长字符”,它的占用空间是可伸缩的。 varchar(255)表示最多能存储255个字符,但最终占用空间以实际存储的值为准,可能实际占用M个字符(M<=255),而char(255)则一定会占用255个字符的控件。
看起来好像varchar是百利而无一害,完爆char对吧?
char VS varchar
char长度固定,不需要考虑边界问题,读写效率高于varchar,适合存储长度固定、频繁读写的数据
varchar长度不固定,但可以通过varchar(10)的方式指定上限,适合存储长度波动、更新不频繁的数据
char的存储长度不够灵活,而varchar则需要浪费1~2个字节来存储当前值的实际长度,且更新会导致重新计算
关于第一点,你可以简单理解为:
char是定长,说了一个字段用3个格子存储就一定是3个格子,所以当你要找第3个数据时,只需要往右数6个格子,那么7~9就存着你要找的数据。而varchar(3)的“3”只代表上限,实际不一定占用3个格子,所以不能直接计算得到位置。
没有最完美的类型,只有最合适的类型。比如,当你需要存储手机号码或者身份证号时,用char(11)、char(18)显然更合适。但存储“个人介绍”时,用varchar更好,因为个人介绍的长度是可变的。
小数类型
| 数据类型 | 占据空间 | 是够精确 |
|---|---|---|
| float | 4个字节 | 非精确 |
| double | 8 个字节 | 非精确 |
| decimal | 每4个字节存9个数字,小数点占一个字节 | 精确 |
对于decimal的大小,比如123456789.987654321,用decimal(18,9)存储,占9个字节,前后各4个字节,小数点一个字节。decimal的效率不如float和double。
当然,很多电商公司其实都是直接存最小单位“分”,也就没有精度问题了。
时间类型
| 数据类型 | 占据空间 | 取值范围 |
|---|---|---|
| date | 3个字节 | 1000-01-01 ~ 9999-12-31 |
| time | 3~6个字节 | -838:59:59 ~ 838:59:59 |
| datetime | 5~8个字节 | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| timestamp | 4~7个字节 | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 |
DATETIME 和 TIMESTAMP的区别:
- 时间范围不同,DATETIME更大,内存稍微大一点
- TIMESTAMP的时间会根据时区变化。比如 SET time_zone=’+10:00’,那么查询后会自动增加10小时
具体跟着公司走就好了,比如我们公司甚至没用时间类型,直接用Long存秒数。
类型选择小结
更小的通常更好
简单合适就好
尽量避免null(设置NOT NULL,除非业务要求可能NULL)
如果确定不会出现负数,可以使用unsigned
NOT NULL:一定要传递值,且不能为NULL,否则报错
DEFAULT ‘xx’:传不传都可以,不传就使用默认值xx,可以传NULL
NOT NULL DEFAULT ‘xx’:传不传都可以,不传就使用默认值xx,不能传NULL
可以做个实验:
1 | CREATE TABLE `test` ( |
测试:
1 | # age_not_null_default 要么不传,要么传非NULL值,这里选择不传,则插入默认值0 |
语句书写顺序
SELECT … FROM table WHERE … GROUP BY … HAVING … ORDER BY … LIMIT …
除了SELECT,后面几个顺序可以记忆为:温哥华OL,意思是温哥华白领。
关联查询
隐式连接
什么是隐式连接?不用写JOIN关键字的连接。
格式是:
FROM t_a, t_b WHERE或ON 等值连接条件
隐式连接属于内连接,效果等同于:
FROM t_a [INNER] JOIN t_b ON 连接条件
显式连接
内连接
格式:
FROM t_a [INNER] JOIN t_b ON 连接条件
INNER写不写都可以,查询效果和隐式连接一样,连接条件写在ON后面。
如果两个表做等值判断的字段相同,比如 ON t1.id = t2.id 可以改写为 USING(id),但没什么卵用,我要不是这次复习,都不知道这是啥意思。所以尽量别用这种乱七八糟的写法,给同事添堵。
外连接
- LEFT JOIN
- RIGHT JOIN
本质是一样的,换个位置而已。
自连接
格式:
FROM t_a child, t_a parent ON 连接条件
自连接不是一种新的连接形式,它可以用上面的任意一种连接方式,只不过是把同一张表当做两张表,自己和自己关联。
其他的什么自然连接(NATURAL JOIN)、交叉连接(CROSS JOIN)不提了,我反正从来没用过,大家有兴趣自行了解,不徒增大家的记忆负担。
子查询
子查询指的就是在一个查询之中嵌套了其他若干个查询。
子查询通常出现在
WHERE后面:SELECT name FROM table_a WHERE id IN (SELECT id FROM table_b)
FROM后面:SELECT name FROM (SELECT name, age FROM table_a) temp LEFT JOIN….
EXISTST后面:没用过,大家自己可以了解一下(很真实)
放在FROM后的子查询可以看做一张临时表,WHERE后面的子查询就是动态的查询条件而已。