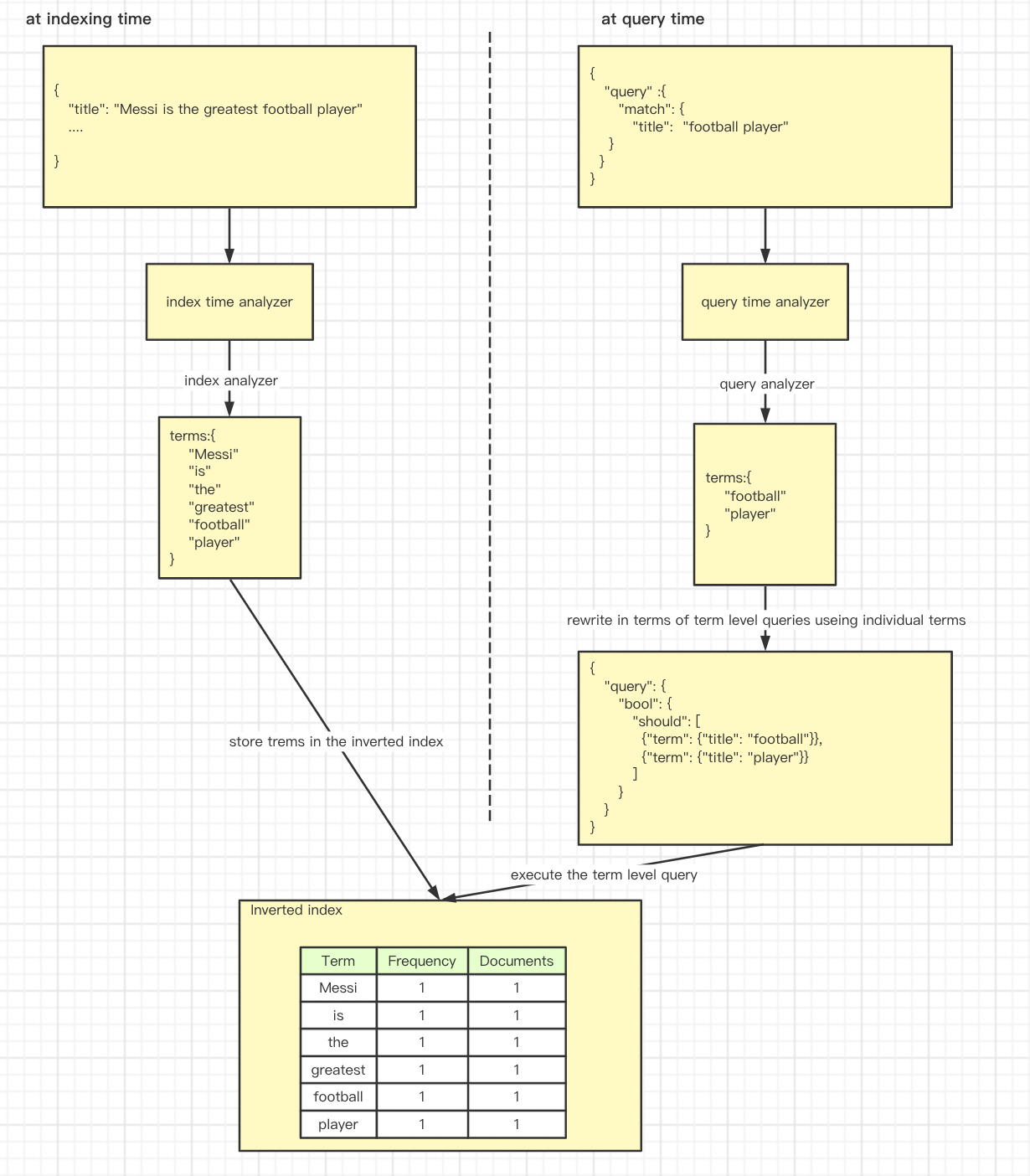
analysis
analysis, 中文意思分析,指的是es在文档发送之前对文档正文的执行过程,以添加到inverted index, 这一过程包含一下几个步骤:
- 使用字符过滤器过滤字符,由char filter完成
- 分词,将input按指定的规则分割为多个token, 由tokanizer完成
- token过滤, 将上一步的tokens按一定规则进行处理, 由token filter完成
- 存入索引
经过 analyzer 处理过后的文档最终以 Inverted Index 的形式保存于 Elasticsearch 中:
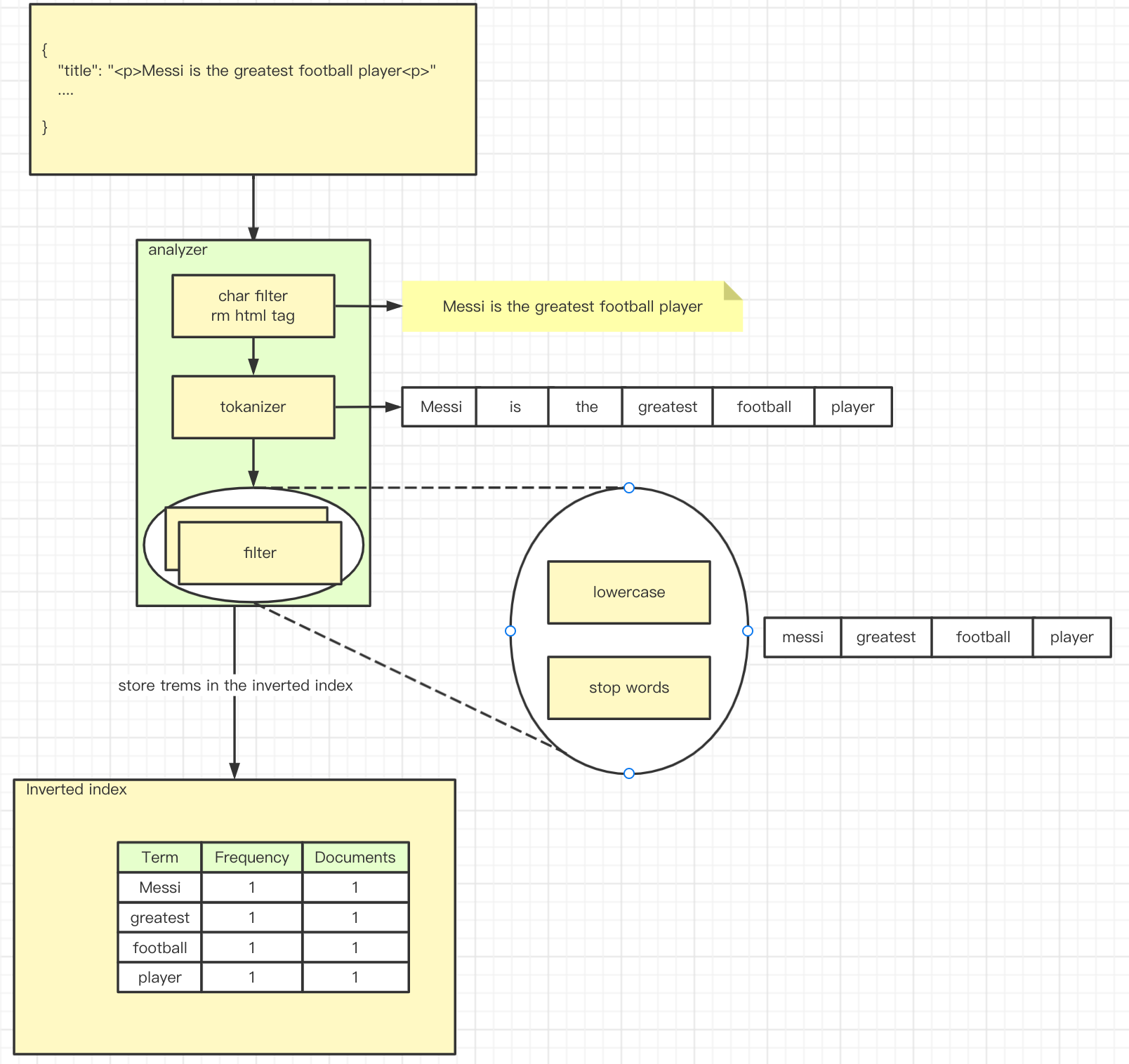
上图中的analyzer, 一般称之为分析器, 由三个部分组成
char filter 字符过滤器,是处理文档正文或搜索输入的第一步, 官方文档
tokenizer 分词器, 顾名思义, 它的作用就是分词, 会输出一个token stream
filter tokens过滤器,对token stream二次处理,token过滤器不允许更改每个token的位置或字符偏移量。官方文档, 常用的有
- lowercase 将所有token转为小写
- stop 将停用词从token流中删除
- synonym 将同义词添加到token流中
- edge_ngram 指定最细粒度和最粗粒度,对token流进行二次分词
analyzer 是char filters、tokenizer和tokens filters的组合,tokenizer代表分词器,它负责将一串文本根据词典分成一个个的词,输出的是tokens数据流,一个analyzer有且只有一个tokenizer。token filter则是对分词之后的结果进行处理,例如大小写转换、关联同义词、去掉停用词、不同国家语言映射转换等,一个analyzer可以有0个或多个filter。
analyzer 只作用于text 类型的字段,而对于 keyword 类型的字段,它将不被分析和分词。keyword 字段被用于精确匹配及聚合。
analyzer的使用场景
1.建立索引的时候, 分析文档正文用于 indexing
2.搜索的时候, 分析input 用于searching