基于IK分词器二开的一点归纳
背景: IK 分词器作为一款广泛应用于中文文本处理的工具,在实际使用场景中,虽然提供了基本的分词功能,但随着业务需求的日益复杂和多样化,其原生功能逐渐显现出一定的局限性。例如,在特定领域的专业文本处理中,可能需要针对行业术语、品牌名称、产品型号等进行更精准的识别和分类;在大规模数据处理时,对分词效率和词典更新的实时性也提出了更高的要求。
为了满足这些不断增长的业务需求,提升文本处理的质量和效率,对 IK 分词器进行二次开发成为了一种必要的手段。通过深入研究 IK 分词器的源码,我们可以根据具体业务场景,定制个性化的分词逻辑,优化词典管理,改进分词算法,从而实现更符合实际需求的文本处理功能。
1.源码分析

我们需要关注的是cfg , core , dic三个包 ,这其中包含了ik分词器的主类, 主配置类、词元类、 词典类等关键类,后续对ik分词器的改造也是围绕这三个包来展开的
core包括了IK的分词器接口ISegmenter,分词器核心类IKSegmenter,语义单元类Lexeme,上下文AnalyzeContext,以及子分词器LetterSegementer(英文字符子分词器),CN_QuantifierSegmenter(中文量词子分词器),CJKSegmenter(中日韩字符分词器),
dic包括了词典类Dictionary,词典树分段类DictSegmenter,用来记录词典匹配命中记录的类Hit
1.词典初始化
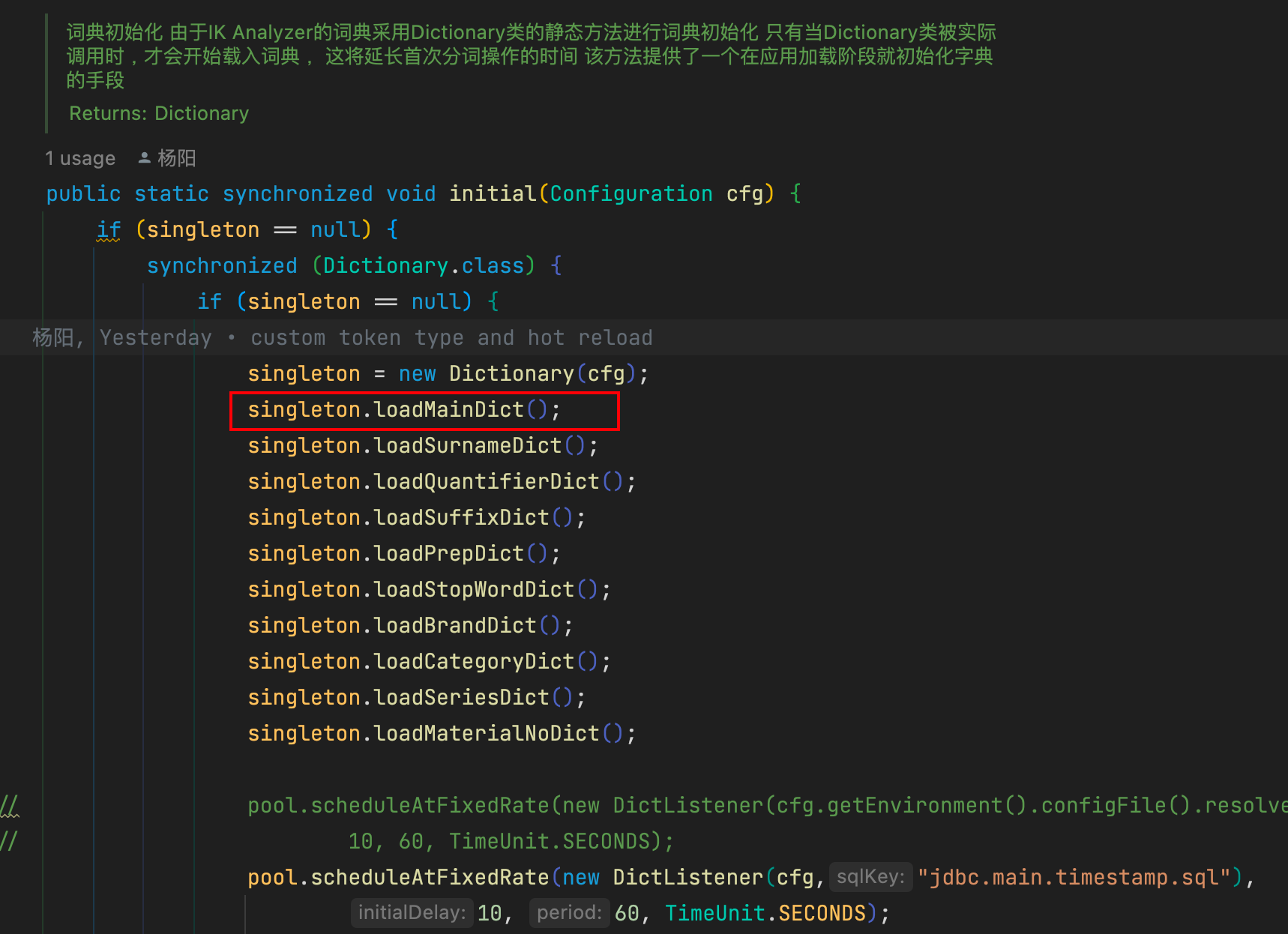
在分词器IKSegmenter首次实例化时,默认会根据DefaultConfig找到主词典和中文量词词典路径,同时DefaultConfig会根据classpath下配置文件IKAnalyzer.cfg.xml,找到扩展词典和停止词典路径,可以在该配置文件中配置自己的扩展词典和停止词典。
找到词典路径后,初始化Dictionary.java,Dictionary是单例的。在Dictionary的构造函数中加载词典。Dictionary是IK的词典管理类,真正的词典数据是存放在DictSegment中,该类实现了一种树结构,如下图。
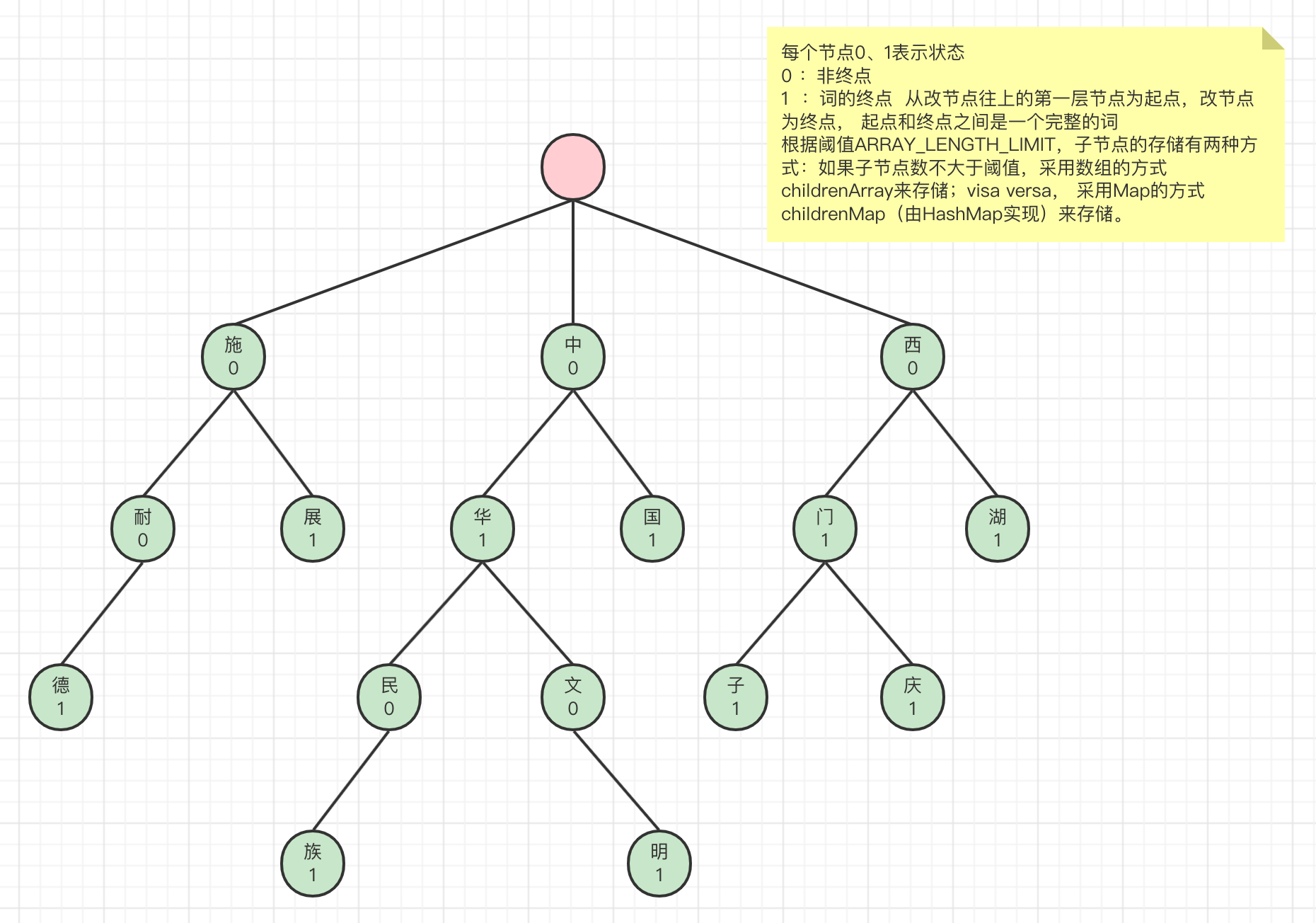
比如,要对字符串”施耐德继电器”进行分词,首先拿到字符串的第一个字符’施’,在上面的词典树中可以匹配到’施’节点,然后拿到字符串第二个字符’耐’,从上一个节点’施’往下找,找到了’耐’节点,’耐’节点是一个非终点节点,继续往下找到’德’节点,’德’节点是终点节点,所以’施耐德’是一个词
Dictionary中默认有三个DictSegment对象, _MainDict , _QuantifierDict , _StopWords , 分别是主词典, 中文量词词典, 停用词词典(停用词词典中的词在分词时将会被忽略)
Dictionary加载主词典,将主词典保存到它的_MainDict对象中,加载完主词典后,加载扩展词典,扩展词典同样保存在_MainDict中。
fillSegment方法是DictSegment加载单个词的核心方法,charArray是词的字符数组,先是从存储节点搜索词的第一个字符,如果不存在则创建一个节点用于存储第一个字符,后面递归存储,直到最后一个字符。
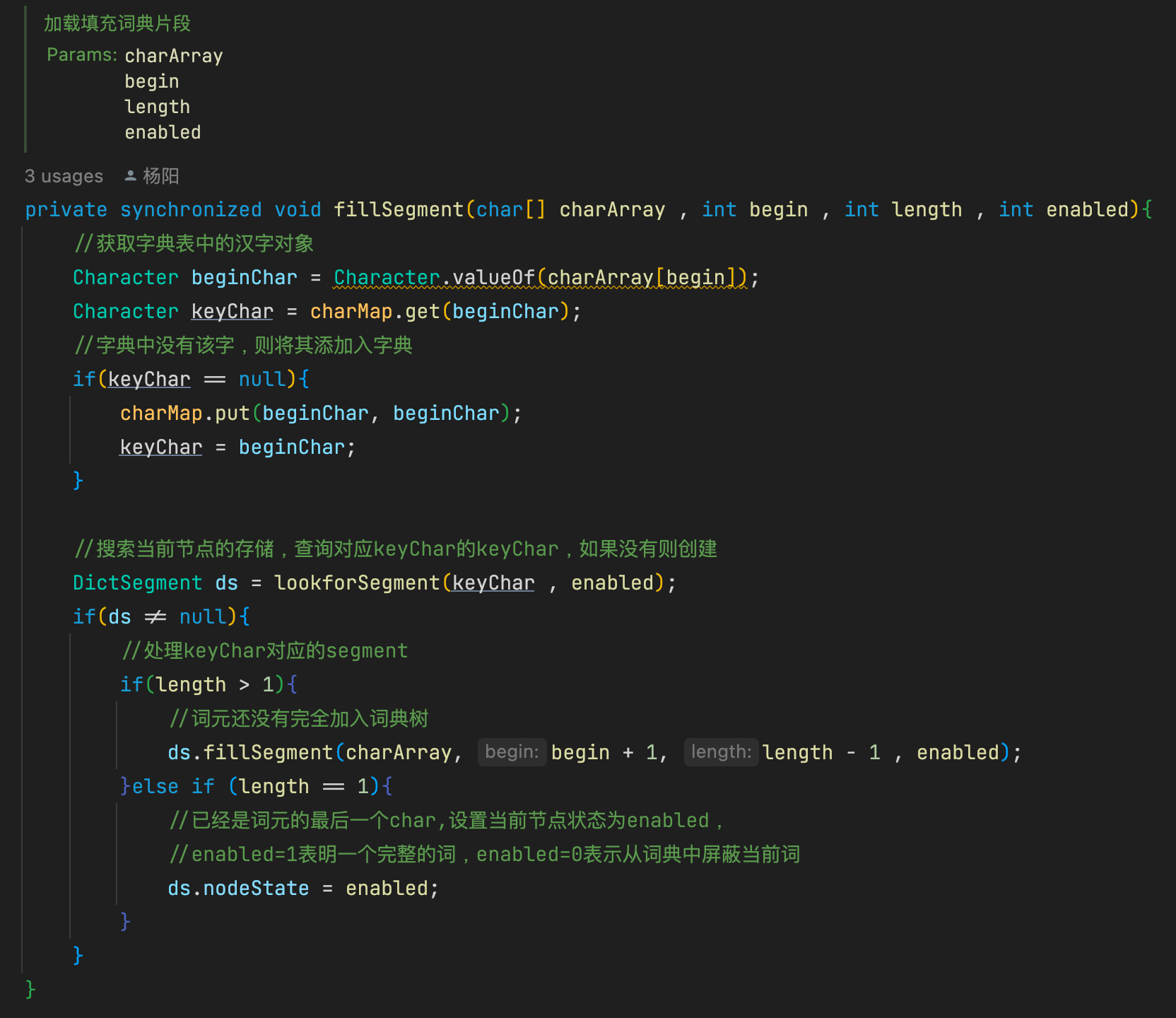
子节点如果存粹用map存储,会比较浪费空间,因此ik采用了一种折中的方式。就是根据子节点的数量对存储结构进行调整,如果子节点的数量小于等于3,则采用数组存储,如果子节点的数量大于3,采用map存储。其中的nodeState就是用来标记当前节点
因为HashMap需要预先分配内存,所以可能存在浪费现象;但是如果全用数组存,后续采用二分查找时无法获得O(1)的时间复杂度。所以这里采用了两种方式,子节点少时用数组存,子节点多时则迁移至HashMap。
2.自定义词典
了解了主词典的加载流程,只需要照猫画虎就行, 自定义几个DictSegment对象,如_BrandDic , _CategoryDic , _MaterialNoDic 等 , 在config文件夹中创建对应的dic文件
编写字典加载方法
在initial方法中调用加载方法,在Dictionary对象创建时会调用此方法,将对应字典加载入内存
3.基于词典的切分
在 IK 分词器中,基于词典的切分是其核心功能之一。当对文本进行分词时,分词器会从文本的起始位置开始,逐个字符地与词典中的词条进行匹配。它会根据已加载的词典树结构,从根节点开始,沿着字符路径向下查找。例如,对于输入文本 “智能电网技术的发展”,分词器首先会获取 “智” 这个字符,然后在词典树中查找是否存在以 “智” 开头的词条。如果找到,会继续获取下一个字符 “能”,并在 “智” 节点的子节点中查找是否有 “能” 节点。以此类推,不断匹配字符,直到找到完整的词条或者无法继续匹配为止。
在这个过程中,IK 分词器会充分利用词典树的结构特点来提高匹配效率。由于词典树的存储结构根据子节点数量进行了优化,当子节点数量较少时使用数组存储,这样可以通过快速的顺序查找来定位字符;而当子节点数量较多时采用 Map 存储,通过键值对的方式能够更高效地查找字符。这种混合存储方式使得在不同情况下都能尽量减少查找时间,提高分词速度。
4.分词模式
IK 分词器提供了多种分词模式,以满足不同场景下的需求。其中最常见的有细粒度分词模式和粗粒度分词模式。
细粒度分词模式旨在尽可能细致地将文本切分成最小的语义单元。在这种模式下,分词器会对文本进行深度分析,将句子中的词语、短语甚至一些特定的组合都尽可能地拆分出来。例如,对于句子 “中国人民解放军是一支强大的军队”,细粒度分词可能会将其拆分为 “中国”“人民”“解放军”“是”“一支”“强大”“的”“军队” 等多个词元。这种模式适用于需要对文本进行详细语义理解和分析的场景,如文本挖掘、知识图谱构建等。
粗粒度分词模式则更注重将文本切分成较大的语义块,以获取更宏观的语义信息。在处理上述句子时,粗粒度分词可能会将其拆分为 “中国人民解放军”“是”“一支强大的军队” 等。这种模式在一些对文本整体语义把握更为重要,而不太关注细节词语的场景中较为适用,比如文档分类、主题提取等。
除了这两种基本模式外,IK 分词器还支持用户自定义分词模式。用户可以根据具体业务需求,通过调整分词器的配置参数或者编写自定义的分词规则,来实现符合自身业务特点的分词方式。例如,在特定领域的专业文档处理中,可以根据领域术语的特点定义专门的分词模式,使得分词结果更贴合业务需求,提高后续文本处理的准确性和效率。
5.匹配定义词性
自定义的字典加载完成后,下一步就是使用词元匹配词典来确认词性,以品牌词典举例, 分词器在获取词元的时候会调用分词器主类IKSegmenter中的next()方法来获取下一个词元,并判断是否为停用词, 我们可以在这里动一些手脚, 通过匹配词典,来判断当前词元的词性

isBrand()方法调用DictSegmenter中的match()方法,品牌词已经加载至一个字典树之内,所以整个过程也就是一个从树根层层往下走的一个层层递归的方式,首字符匹配到一个节点后,判断下面是否还有节点,有就继续往下匹配;匹配的结果一共三种UNMATCH(未匹配),MATCH(匹配), PREFIX(前缀匹配)。
1 | /** |
匹配成功则将当前词元的type设置为brand,没有匹配上则继续匹配其他词典,直至结束.
6基于规则的歧义判断
在中文分词中,歧义判断是一个复杂且关键的环节。IK 分词器在进行分词时,经常会遇到一些可能产生歧义的情况。例如,对于句子 “从小学到大学”,既可以切分为 “从 / 小学 / 到 / 大学”,也可以切分为 “从小 / 学到 / 大学”。
为了处理这些歧义,IK 分词器采用了基于规则的方法。它内置了一系列预先定义好的规则来对可能产生歧义的分词结果进行判断和调整。这些规则是基于对大量中文语言现象的分析和总结得出的。
其中一种常见的规则是基于词语的词性和语义搭配。例如,某些词语在特定的词性组合下更倾向于一种分词方式。如果 “从” 作为介词,后面更可能跟随一个表示地点或范围的名词短语,如 “小学”,那么在这种情况下,更倾向于将 “从小学” 作为一个整体,而不是将 “从小” 单独拆分出来。
另外,IK 分词器还会考虑词语在句子中的上下文信息。比如,当 “到” 前面是一个表示地点或时间范围的词语时,更有可能与前面的词语构成一个整体的语义单元。在 “从小学到大学” 这个句子中,根据上下文,“到大学” 更符合逻辑上的语义表达,所以会优先选择这种分词方式。
同时,IK 分词器在处理歧义时还会参考语言习惯和常见用法。对于一些常见的固定搭配或习惯用语,会按照约定俗成的方式进行分词。例如 “中华人民共和国”,会始终作为一个整体进行分词,而不会拆分成其他形式。
通过这些基于规则的歧义判断机制,IK 分词器能够在多种可能的分词结果中选择最符合语义逻辑和语言习惯的一种,从而提高分词的准确性和质量,为后续的文本处理任务提供更可靠的基础。在实际应用中,这些规则不断地根据新的语言现象和用户反馈进行优化和完善,以适应不断变化的中文语言环境和多样化的业务需求。例如,在处理一些新兴的网络用语或专业术语时,会及时更新规则,确保分词的有效性。
2.热更新
基于数字资产保密条款, 热更新相关代码不予展示