IK Aanlysis 文档
1.源码分析

我们需要关注的是cfg , core , dic三个包 ,这其中包含了ik分词器的主类, 主配置类、词元类、 词典类等关键类,后续对ik分词器的改造也是围绕这三个包来展开的
core包括了IK的分词器接口ISegmenter,分词器核心类IKSegmenter,语义单元类Lexeme,上下文AnalyzeContext,以及子分词器LetterSegementer(英文字符子分词器),CN_QuantifierSegmenter(中文量词子分词器),CJKSegmenter(中日韩字符分词器),
dic包括了词典类Dictionary,词典树分段类DictSegmenter,用来记录词典匹配命中记录的类Hit
1.词典初始化
在分词器IKSegmenter首次实例化时,默认会根据DefaultConfig找到主词典和中文量词词典路径,同时DefaultConfig会根据classpath下配置文件IKAnalyzer.cfg.xml,找到扩展词典和停止词典路径,可以在该配置文件中配置自己的扩展词典和停止词典。
找到词典路径后,初始化Dictionary.java,Dictionary是单例的。在Dictionary的构造函数中加载词典。Dictionary是IK的词典管理类,真正的词典数据是存放在DictSegment中,该类实现了一种树结构,如下图。
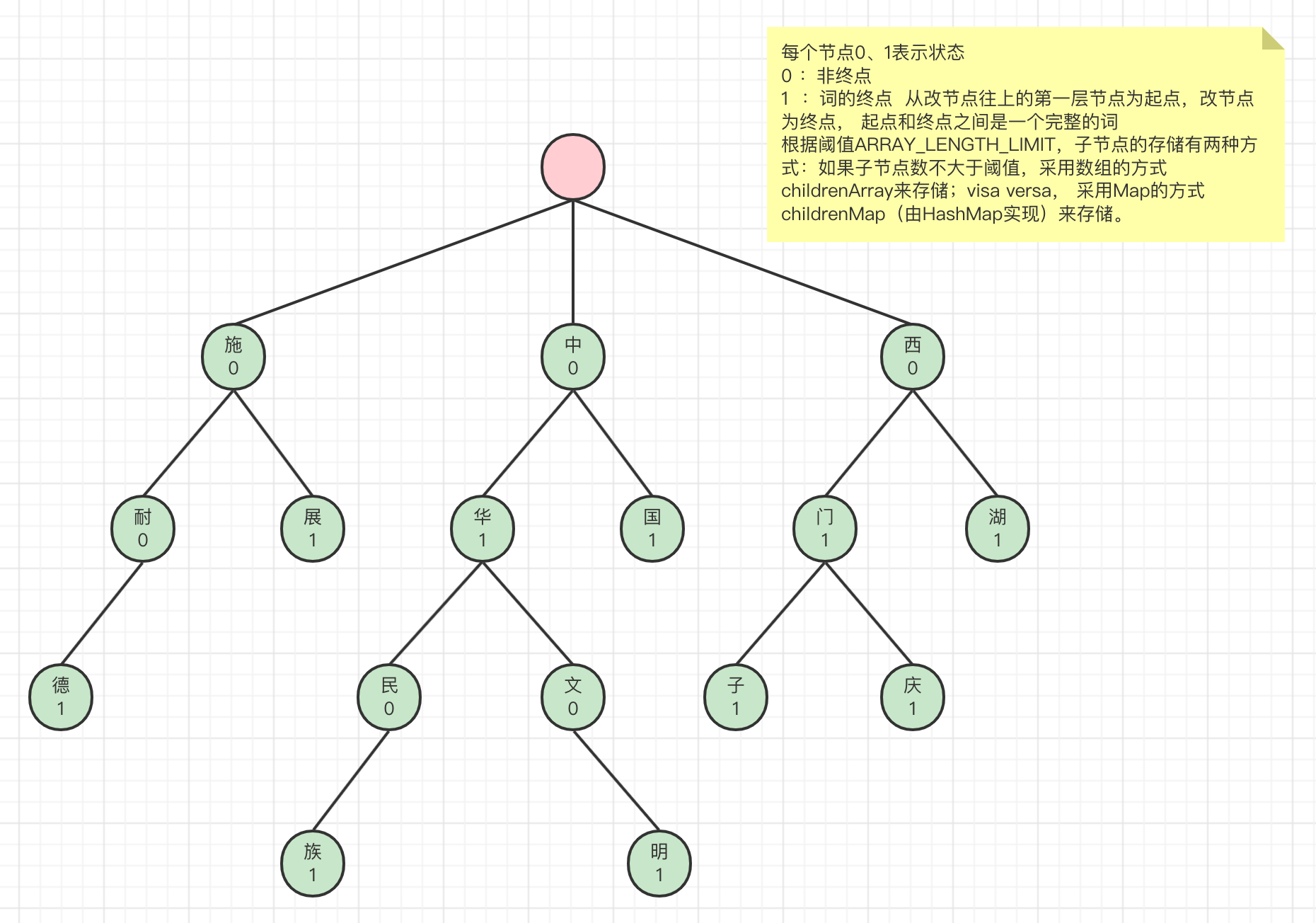
比如,要对字符串”施耐德继电器”进行分词,首先拿到字符串的第一个字符’施’,在上面的词典树中可以匹配到’施’节点,然后拿到字符串第二个字符’耐’,从上一个节点’施’往下找,找到了’耐’节点,’耐’节点是一个非终点节点,继续往下找到’德’节点,’德’节点是终点节点,所以’施耐德’是一个词
Dictionary中默认有三个DictSegment对象, _MainDict , _QuantifierDict , _StopWords , 分别是主词典, 中文量词词典, 停用词词典(停用词词典中的词在分词时将会被忽略)
Dictionary加载主词典,将主词典保存到它的_MainDict对象中,加载完主词典后,加载扩展词典,扩展词典同样保存在_MainDict中。
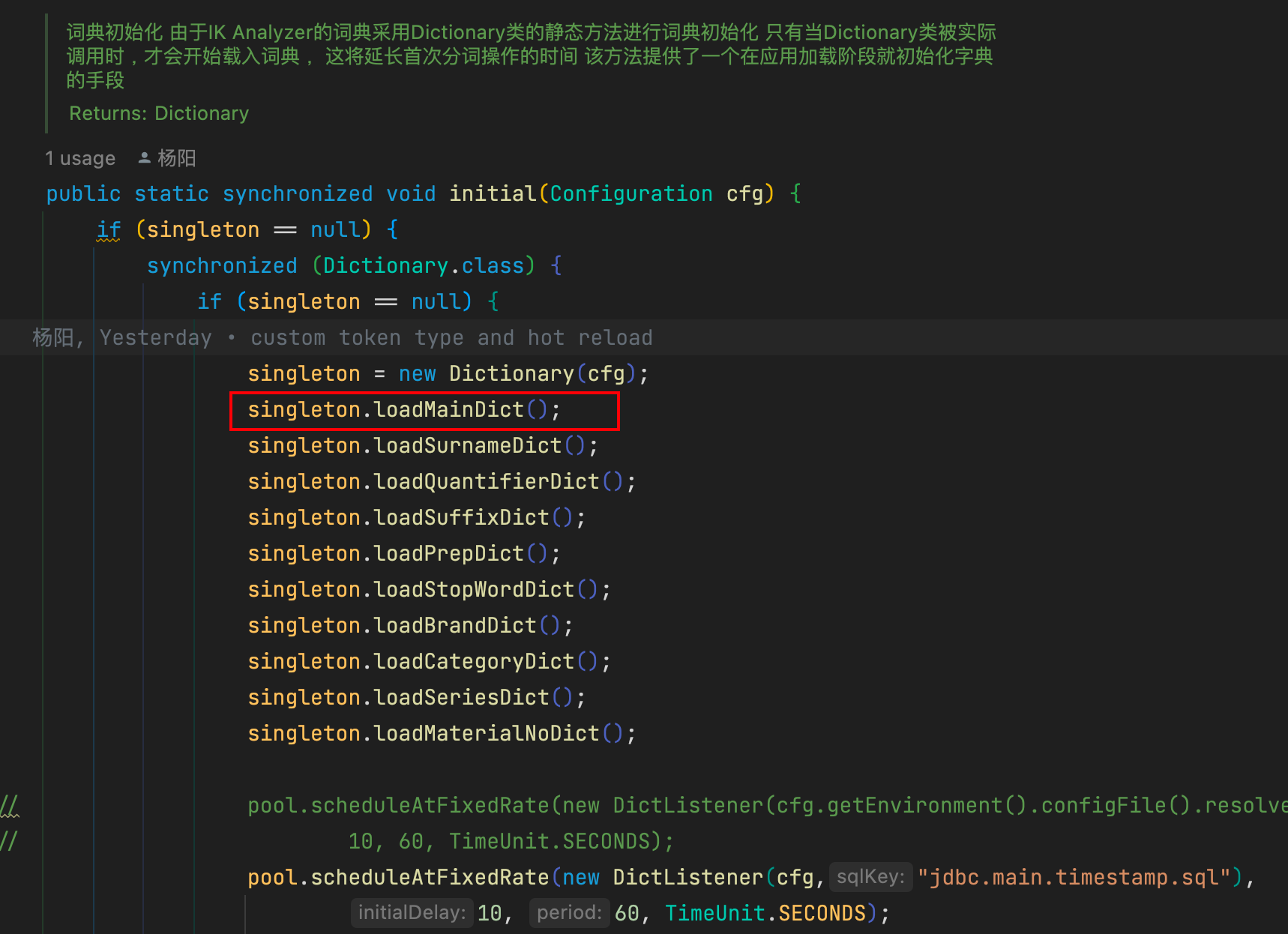
fillSegment方法是DictSegment加载单个词的核心方法,charArray是词的字符数组,先是从存储节点搜索词的第一个字符,如果不存在则创建一个节点用于存储第一个字符,后面递归存储,直到最后一个字符。
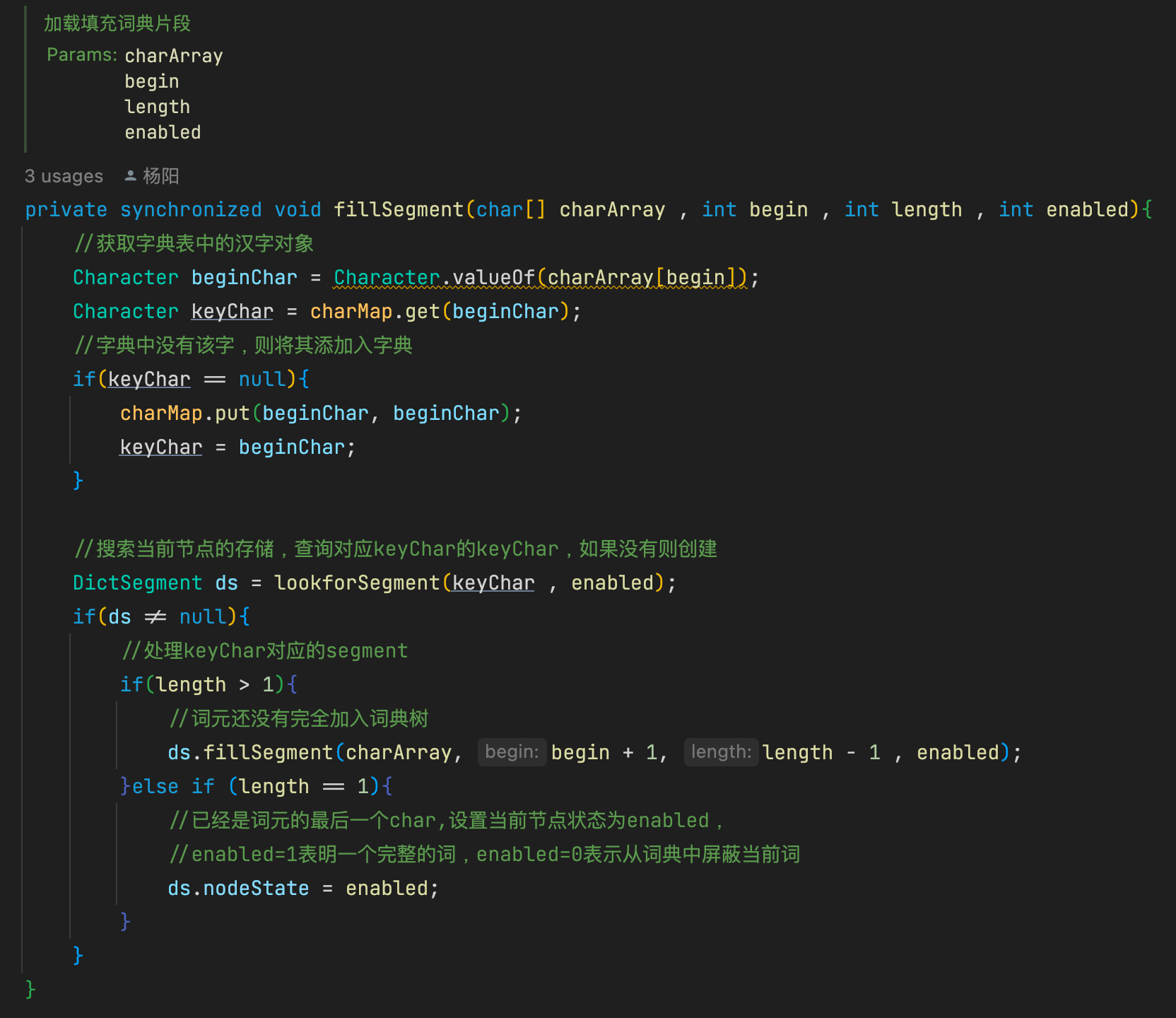
子节点如果存粹用map存储,会比较浪费空间,因此ik采用了一种折中的方式。就是根据子节点的数量对存储结构进行调整,如果子节点的数量小于等于3,则采用数组存储,如果子节点的数量大于3,采用map存储。其中的nodeState就是用来标记当前节点
因为HashMap需要预先分配内存,所以可能存在浪费现象;但是如果全用数组存,后续采用二分查找时无法获得O(1)的时间复杂度。所以这里采用了两种方式,子节点少时用数组存,子节点多时则迁移至HashMap。
2.自定义词典
了解了主词典的加载流程,只需要照猫画虎就行, 自定义几个DictSegment对象,如_BrandDic , _CategoryDic , _MaterialNoDic 等 , 在config文件夹中创建对应的dic文件
编写字典加载方法
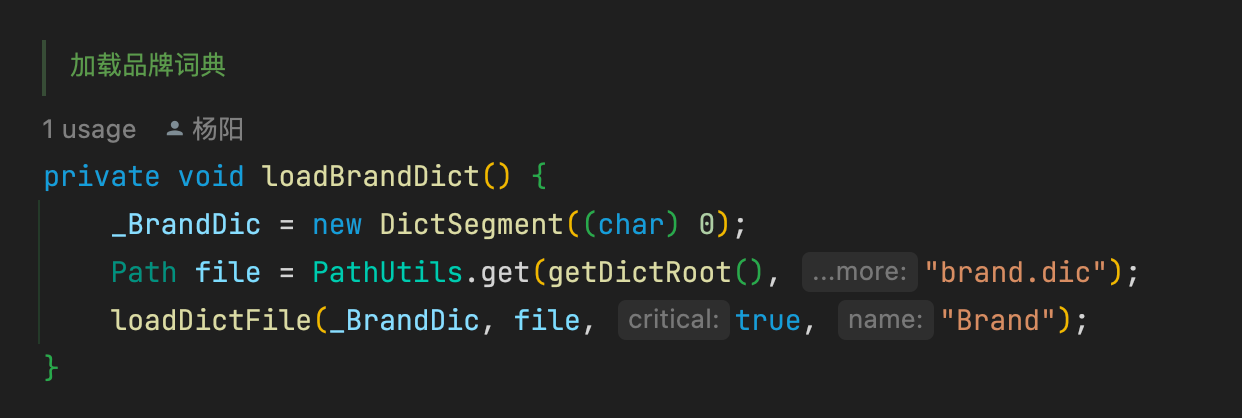
在initial方法中调用加载方法,在Dictionary对象创建时会调用此方法,将对应字典加载入内存
3.基于词典的切分
4.分词模式
5.匹配定义词性
自定义的字典加载完成后,下一步就是使用词元匹配词典来确认词性,以品牌词典举例, 分词器在获取词元的时候会调用分词器主类IKSegmenter中的next()方法来获取下一个词元,并判断是否为停用词, 我们可以在这里动一些手脚, 通过匹配词典,来判断当前词元的词性

isBrand()方法调用DictSegmenter中的match()方法,品牌词已经加载至一个字典树之内,所以整个过程也就是一个从树根层层往下走的一个层层递归的方式,首字符匹配到一个节点后,判断下面是否还有节点,有就继续往下匹配;匹配的结果一共三种UNMATCH(未匹配),MATCH(匹配), PREFIX(前缀匹配)。
1 | /** |
匹配成功则将当前词元的type设置为brand,没有匹配上则继续匹配其他词典,直至结束.